

Optimizing Workload and Compute in Kubernetes using descheduler
As the state of Kubernetes clusters can change over time due to its dynamic nature, it may be necessary to relocate running pods to different nodes.




Photo by Tyler Casey on Unsplash
Binding and placement of pending Pods on to respective Nodes are managed by a scheduler in Kubernetes called Kube-scheduler. Configurable scheduler policies, plugins, and extensions manage the placement decisions, often called predicates and priorities. The decision of a scheduler is based on the actual condition or state of the Cluster at the time when the Pod is requested to be deployed (scheduled). Since the Kubernetes cluster may change its state by updating or change of labels, taints, tolerations, or even by introducing new nodes into it. There may be a desire of relocating a pod from one node to another, a.k.a descheduler.
So before we explore the descheduler, we might need to recap how the scheduler works. The scheduling decision is based on 4 stages or extension points, these are:
Scheduling Queue
Filtering
Scoring
Binding
There can be multiple plugins installed on these extension points, e.g: PrioritySort plugin on the queue, NodeResourceFit, and NodeName plugin on the filtering extension point. Because of the highly extensible nature of Kubernetes, it makes it possible first to customize which plugin goes where and also allows us to write our custom plugins. It also gives us the ability to add a plugin in the post and pre-stages of the extension points.
Now since the scheduling decision is based on a decision taken place by multiple plugins and their placement in the extension points at the time of scheduling, so it is highly possible that the original scheduling decision is not valid anymore.
When do you need a Descheduler
Due to the dynamic nature of the Kubernetes Cluster, there could be several reasons why you may want to evict (deschedule) a Pod from a node:
To improve cluster performance and availability by redistributing pods to optimize resource usage and reduce contention for resources.
To minimize downtime by automatically rescheduling pods on healthy nodes when a node fails.
To help with scaling by removing underutilized pods and redistributing them to nodes where they can be better utilized.
To improve security by ensuring that only authorized pods are running on the cluster.
To enforce policies such as inter-pod anti-affinity, where it can detect and deschedule the pods that don't conform to the policy and redistribute the pods to other nodes.
To improve cost-efficiency by reducing wastage of resources by identifying and removing duplicate pods and rescheduling them.
Below is the list of different scenarios where the use of a descheduler is unavoidable:
1. A new node is introduced in a cluster
You have just introduced a new node in the cluster and want to distribute the workload evenly. Without descheduling, your pods may reside on the original nodes for ages, and due to this adding new nodes will not have any immediate performance benefits. Descheduling pods and redistributing them on new nodes can help improve resource usage and ensure that resources are distributed evenly across the cluster. By spreading the pods across different nodes, the load on individual nodes is reduced resulting in improved performance and stability of the cluster. It will also help the default scheduler and auto-scaler to adjust the number of replicas to match the new capacity and resource available in the cluster.

2. Node labels are updated
A node label update can affect different scenarios and the original scheduling decision may not be appropriate for certain pods. Here are some of the important ones:
Node Affinity: Node affinity allows for pods to be scheduled based on the labels assigned to a node. If the labels of a node is changed, it may no longer match the node affinity rules of a pod, which can lead to an undesired state.
Node Selector: Node selector allows to schedule pods on specific nodes based on the node labels, if a label is updated then these decisions are no longer valid and require eviction.
Failure Domain: Node labels can be used to indicate the failure domain of a node like a region, rack, or zone, which can be used to schedule the pods to spread across multiple failure domains. An intelligent deschduler will ensure the high availability of services by taking optimum descheduling decisions.

3. Node failure requires Pods to be moved
It is important to deschedule pods on a failed node because:
High availability: When a node fails, the pods running on that node can become unavailable, and this can have a significant impact on the availability of the applications and services running on the cluster. By descheduling the pods on a failed node, the cluster can automatically reschedule the pods on healthy nodes, which can help to minimize downtime and improve availability.
Resource Utilization: A failed node can cause a significant drain on resources such as CPU and memory. By descheduling the pods on a failed node, the cluster can free up these resources, which can be used more efficiently by other pods, improving overall cluster performance.
Auto Scaling: A failed node can impact the scaling of pods. By descheduling the pods running on a failed node, the auto-scaler can automatically adjust the number of pods running on healthy nodes to maintain the desired number of replicas.
Networking: Descheduling pods on a failed node can help prevent networking issues, such as IP conflicts or service outages, which may be caused by pods running on a failed node.
Security: Descheduling pods running on a failed node can help prevent security risks. A failed node can be compromised and running malicious pods on a compromised node can pose a significant risk to the cluster.

Descheduling pods on failed nodes are important to ensure that the cluster remains highly available, that resources are used efficiently, and that the auto-scaler can adjust the number of replicas running, avoiding networking issues and maintaining security.
4. Remove Duplicates
Duplicate pods in a Kubernetes cluster can cause several issues that can negatively impact the performance and availability of the cluster. Some reasons why it's important to remove duplicate pods from a node running in Kubernetes include:
Resource Utilization: Duplicate pods consume resources such as CPU and memory that could be used more efficiently by other pods. This can cause resource contention, which can lead to delays in container startup times and negatively impact the overall performance of the cluster.
Networking: Each pod consumes network resources such as IP addresses, and having multiple pods with the same IP address can cause networking issues such as IP conflicts, which can cause communication problems between pods and services.
Scalability: Duplicate pods can make it difficult to scale the number of pods running in a cluster. For example, if a Deployment controller creates multiple replicas of a pod, each replica will have a different replica number and the same pod name which can confuse when trying to scale the number of replicas.
Security: Having duplicate pods can make it difficult to keep track of what is running on a cluster and can open security vulnerabilities. It is important to ensure that all running pods are authorized and that no rogue pods are running.
Cost: Running duplicate pods can result in a waste of resources, which can result in higher costs.
Removing duplicate pods from a node can help to improve the overall performance and availability of a Kubernetes cluster by optimizing resource utilization, reducing network conflicts, improving scalability, security, and reducing costs.

5. Low/High Node Utilization
A descheduler can help distribute load across different nodes in the cluster in several ways:
Balancing resource usage: A descheduler can identify pods that are consuming a disproportionate amount of resources on a node, such as CPU or memory, and move them to other nodes where resources are more available. This can help to balance the resource usage across the cluster and improve overall cluster performance.
Reducing node overcommitment: A descheduler can identify nodes that have a high number of pods running on them and redistribute the pods to other nodes to reduce the number of pods running on the overcommitted node. This can help to reduce contention for resources and improve the overall performance of the cluster.
Improving node utilization: A descheduler can help to identify and remove underutilized pods on a node, and redistribute them to nodes where they can be utilized better. This can help to improve the utilization of resources across the cluster.
6. Pods Violating Inter Pod AntiAffinity
Inter-pod anti-affinity is a feature that allows you to specify rules for how pods should be scheduled in relation to one another. These rules can be used to ensure that pods that belong to the same application or service are spread across different nodes in a cluster, in order to improve availability and reduce the risk of single points of failure.
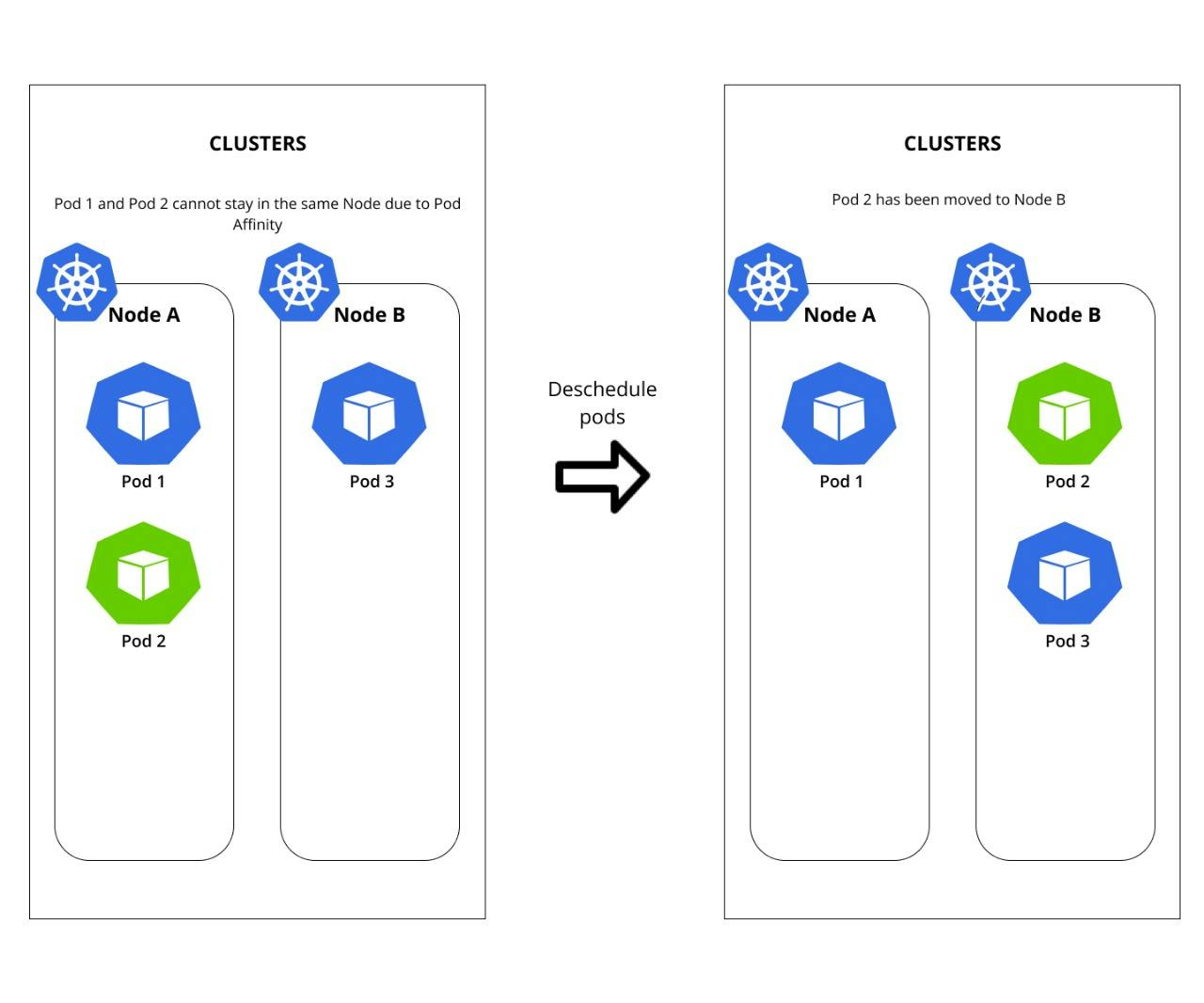
One important reason to use inter-pod anti-affinity is to ensure that pods that need to be highly available, such as database pods, are not scheduled on the same node. If multiple pods that need to be highly available are scheduled on the same node and that node goes down, multiple pods will become unavailable at the same time. Spreading these pods across different nodes can help to mitigate this risk.
Another reason to use inter-pod anti-affinity is to ensure that pods are spread across different zones or regions to improve resiliency in the event of a zone or region failure.
It is important to use a descheduler in this scenario because, despite the best efforts of Kubernetes scheduler, sometimes pods can violate inter-pod anti-affinity rules due to various reasons like over-commitment of resources or other factors. A descheduler can help identify and remove these pods, ensuring they are rescheduled to comply with the specified anti-affinity rules. This can help to improve cluster availability, reduce the risk of single points of failure, and optimize resource utilization.
10. Pods Violating Topology Spread Constraint
Topology spread constraints allow to spread of pods evenly across different nodes, zones, regions, or racks. By descheduling pods that violate these constraints, the cluster can ensure that the resources are utilized more efficiently, pods are spread out to reduce contention of resources, it can guarantee high availability by running the services on multiple nodes, zones, and regions and it can also help minimize the impact of an infrastructure failure by failure domain awareness.
11. Pods Having Too Many Restarts
When a pod has too many restarts, it can indicate that there is an issue with the pod or the node it is running on. Pods that are continuously restarting can destabilize the cluster, can delay container startup times, and negatively impact the overall performance of the cluster. Descheduling such a pod can help the operation teams to understand the issue behind the continuous restarts and stabilize the application and cluster performance.
Conclusion
In summary, a descheduler plays an important role in managing and optimizing the distribution of pods within a Kubernetes cluster. It can help to ensure that the cluster is running at optimal performance, that resources are being used efficiently, and that the cluster is secure and available.